| Joel Sklar Consulting | Home |
XSLT Primer
XSLT BasicsXSLT stands for the Extensible Style Language Transformations. XSLT lets lets you transform either XML or XHTML files into other types of markup documents. For example, you may have an XML data file that needs to be published to the web. To make this file compatible with older browsers, you need to transform the markup tags from XML to HTML. This is easy to do using XSLT, as you will see in the examples below. XSLT is an XML-based language. An XSLT stylesheet is a stand-alone, text based document that contains XSLT style rules. You can apply XSLT stylesheets to either XML or XHTML files - the data must be well-formed, that is, XML compliant. So to understand XSLT you should have a working knowledge of XML. XSLT is powerful because it allows you to manipulate data, rather than just specifying display information as you do with CSS. You can transform tag names, manipulate data order, create attributes from elements, and many other operations. You can also use CSS within XSLT style sheets to add style information, so if you already know CSS you can continue to use it. How Does XSLT Work?An XLST processor reads in a source file of XML data. It matches the XML file to a specified XSLT style sheet. The rules in the XSLT stylesheet specify which data to extract from the input XML document, and how to transform the data to create a new output tree. 
An XSLT style sheet contains a set of template rules. A template rule has two parts: a pattern which is matched against elements in the source tree and a template which forms the result tree. The XSLT style rules extract data from the source document using XPath syntax. The XSLT processor starts document processing at the root element of the input document. It traverses the document tree, matching data patterns to data nodes, extracting data, applying the output template, and repeating by processing additional patterns/templates. Then it creates the output document. 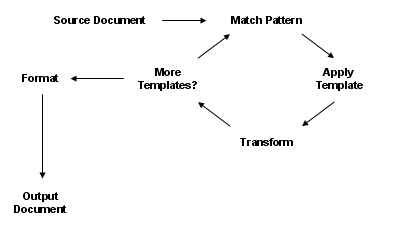
As a simple example, examine the following instance of XML data and fragment of an XSLT stylesheet. This code contains an <xsl:value-of> command to extract the value of the data contained in the article/heading node. In the ouput document the data will be an <h1> element. XML Data <article> <heading>Red Sox Win World Series!</heading> </article> XSLT Stylesheet Rule <h1> <xsl:value-of select="article/heading"/> </h1> This will be the result: <h1> Red Sox Win World Series! </h1> Working with XPATHXSLT uses XPATH expressions to locate data in the input document tree and extract it for transformation. You can't use XSLT without XPATH, so here's enough information to get you started. You can find out more at the W3 XPATH page. XPATH models XML data as a tree of nodes. The nodes can be element, attribute or text data nodes. An XPATH stament locates the contents of the node. For example, compare this XPATH stament and the accompanying data tree: books/book/price/@currency This statement navigates the path through the specified nodes of the tree until it reaches the attribute node "currency." 
XPATH statements allow predicates to evaluate and perform tests on data. These examples show how predicates can narrow the set of data: Find the currentPrice element with a value less than 1000: list/item[currentPrice>1000] Find the currentPrice element with a currency attribute containing the value "US": list/item/currentPrice[@currency="US"] Find the second item element node: list/item[2] XPATH can evaluate expressions and manipulate numbers, strings and booleans to extract subsets of data. These XPATH syntax examples from the W3 XPATH recommendation are a good place to get started. Example #1 - A Basic Style SheetYou manage the web site for a used book store. Let's assume that you have a database of XML data that describes the books in your warehouse. A sample of the XML data is in a file named book.xml. You can also view the data file here. <?xml version="1.0" ?> <book> <title>All about XML</title> <author>Xavier M. Elle</author> <isbn>30-86956-88</isbn> </book> You will need to change the XML tags to HTML for this content to be viewable in a browser. You can use an XSLT stylesheet to transform the XML to HTML. Take a look at the following XSLT stylesheet file, book.xsl. <?xml version="1.0" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <!-- style sheet rules go here --> </xsl:template> </xsl:stylesheet> The first line contains the standard <?xml version="1.0"?> processing instruction. The <xsl:template> and <xsl:stylesheet> elements are "boilerplate", they must be included in all xslt stylesheet files. Notice that both of these elements contain the xsl: prefix. This prefix identifies the xml elements as belonging to the XSLT style language. Next add the standard HTML tags that will appear in the HTML output file. The new elements are shown in bold: <?xml version="1.0" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <head> <title>Book Data</title> </head> <body> <!-- style sheet rules go here --> </body> </html> </xsl:template> </xsl:stylesheet> Notice that these new elements have no xsl: prefix. Any element in an XSL stylesheet that does not have the xsl: prefix gets ouput literally to the new document. These tags will form the basic HTML file we are creating. The next step is to add the XSL rules that will extract information from the XML data file and output it in HTML format. The highlighted rule in the following code extracts the contents of the <title> element and output it as an <h2> element in the new HTML file. <?xml version="1.0" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <head> <title>Book Data</title> </head> <body> <h2> <xsl:value-of select="book/title"/> </h2> </body> </html> </xsl:template> </xsl:stylesheet> Notice the <xsl:value-of> element. This XSL instruction gets the value of the element named in the select attribute. The value "book/title" is the path to the XML data, reflecting that <title> is a child of <book>. The data in the <title> element will be output as an <h2> element in the new HTML file. Finally, add two other instructions to extract the contents of the <author> and <isbn> elements. These will be contained in a <p> element with a <br> between the author and isbn values. <?xml version="1.0" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <head> <title>Book Data</title> </head> <body> <h2> <xsl:value-of select="book/title"/> </h2> <p> <xsl:value-of select="book/author"/> <br /> <xsl:value-of select="book/isbn"/> </p> </body> </html> </xsl:template> </xsl:stylesheet> To get this all to work go back to the original XML data file and add an xml-stylesheet processing instruction. This instruction points to the newly created XSLT file book.xsl. You can view the completed XSLT file here. <?xml version="1.0" ?> <?xml-stylesheet href="book.xsl" type="text/xsl" ?> <book> <title>All about XML</title> <author>Xavier M. Elle</author> <isbn>30-86956-88</isbn> </book> To see the results of this XSLT transformation, view this file. Example #2 - Extracting and Sorting Multiple ValuesYour bookstore is growing and you have multiple data records to manage. You now have a new data file named named authors.xml. You can view the data file here. <?xml version="1.0" ?> <authorlist> <title>List of Authors</title> <author period="classical"> <name>Sophocles</name> <nationality>Greek</nationality> </author> <author period="modern"> <name>Tolstoy, Leo</name> <nationality>Russian</nationality> </author> <author period="modern"> <name>Pushkin, Alexander</name> <nationality>Russian</nationality> </author> <author period="classical"> <name>Plato</name> <nationality>Greek</nationality> </author> <author period="modern"> <name>Hugo, Victor</name> <nationality>French</nationality> </author> </authorlist> Notice that the data file has multiple <author> elements, each with a consistent child element structure. You can use an <xsl:for-each> instruction to extract values from multiple records. Take a look at the following XSLT stylesheet file, authorlist.xsl. This file contains the default elements you will find in any XSLT stylesheet. <?xml version="1.0" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <!-- style sheet rules go here --> </xsl:template> </xsl:stylesheet> Next add the standard HTML tags that will appear in the HTML output file, plus an <xsl:value-of> to extract the contents of the <title> element from the XML file. The new elements are shown in bold: <?xml version="1.0" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <head> <title>Author List</title> </head> <body> <h1><xsl:value-of select="authorlist/title"/></h1> </body> </html> </xsl:template> </xsl:stylesheet> Now you can add an <xsl:for-each> instruction to loop through the list of authors. The <xsl:for-each> element is always a container for other instructions, as you can see in the code sample below. Within the <xsl:for-each> you can add a <xsl:value-of> that extracts the authors name from the list of authors. The <p> elements that surround the <xsl:value-of> will be literally output to the HTML file. The following code sample shows the new code. <?xml version="1.0" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <head> <title>Author List</title> </head> <body> <h1><xsl:value-of select="authorlist/title"/></h1> <xsl:for-each select="authorlist/author"> <p><xsl:value-of select="name"/></p> </xsl:for-each> </body> </html> </xsl:template> </xsl:stylesheet> You can add multiple instructions within an <xsl:for-each>. The new code below shows the addition of another <xsl:value-of> to get the attribute value from each author element. Notice the syntax using the @ sign to get the attribute value. This works because the <xsl:for-each> instruction locates the processor at authorlist/author. The location of child elements and attributes is relative from that node. An <xsl:sort> instruction lets you sort the results in descending order. <?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <head> <title>Author List</title> </head> <body> <h1><xsl:value-of select="authorlist/title"/></h1> <xsl:for-each select="authorlist/author"> <xsl:sort select="name" order="descending"/> <p><xsl:value-of select="name"/><br/> <i>Period</i>: <xsl:value-of select="@period"/> </p> </xsl:for-each> </body> </html> </xsl:template> </xsl:stylesheet> The result of this transformation looks like this in the browser. 
Here is the completed stylesheet file authorlist.xsl. You can view the result of the transformation and get the XML source code here. Use View -> Source in your browser to view the XML code. |